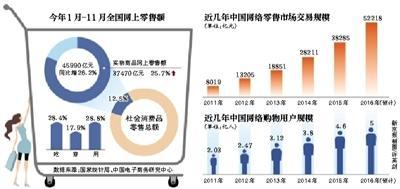
隨著移動互聯網的深入滲透和消費代際的更迭,中國母嬰市場正經歷一場深刻的變革。作為國內領先的電商運營服務商,若羽臣敏銳地洞察到這一趨勢,精準切入母嬰電商賽道,并深刻認識到,成功的核心在于深刻理解并滿足新生代寶媽這一核心消費群體的獨特訴求,從而構建起堅實的競爭壁壘。
新生代寶媽(通常指85后、90后乃至95后母親)是伴隨著互聯網成長起來的一代。她們的消費行為呈現出鮮明的特征:信息獲取高度依賴社交媒體與垂直社群(如小紅書、母嬰App),信賴“種草”與口碑推薦;追求產品的品質、安全與科學性,樂于為專業和精細化付費;注重消費的便捷性與體驗感,對一站式購物、個性化服務有更高要求;她們也是內容消費的主力軍,渴望通過知識獲取緩解育兒焦慮。這些訴求共同構成了母嬰電商發展的新邏輯。
若羽臣的電子商務經營策略正是圍繞這些核心訴求展開的系統性布局:
- 深度內容營銷與社群運營:若羽臣不再局限于傳統的流量采買,而是大力投入內容生態建設。通過與合作品牌共創高質量的育兒知識科普、產品深度測評、使用場景短視頻等內容,在各大社交與內容平臺建立專業、可信的品牌形象。積極運營私域社群,將分散的寶媽消費者聚合起來,提供專屬咨詢、互動活動與福利,構建高粘性的用戶社區,將“流量”轉化為可持續的“留量”。
- 數據驅動的精細化產品運營:利用強大的數據分析能力,若羽臣能夠精準洞察不同細分年齡段寶寶的需求以及寶媽們的購物偏好。在此基礎上,為合作品牌提供從市場趨勢分析、產品概念建議到供應鏈優化的全方位支持,助力品牌推出更貼合市場需求的產品。在電商運營端,實現千人千面的商品推薦與營銷活動,提升轉化效率。
- 打造全渠道無縫體驗:理解新生代寶媽對便捷性的要求,若羽臣積極整合線上多渠道資源(如天貓、京東、抖音、快手等),并探索線上線下的融合。通過統一的會員體系和服務標準,確保消費者在任何觸點都能獲得一致、流暢的購物與服務體驗。物流的時效性與可靠性、售后服務的專業與溫情,都成為增強用戶忠誠度的重要環節。
- 強化品牌信任與安全背書:針對寶媽群體對安全與品質的極致關注,若羽臣在選品與合作上設立高標準。嚴格審核供應商資質與產品認證,并積極傳遞品牌的研發實力、原料溯源、權威檢測等信息。通過透明化溝通,建立起堅實的信任基礎,這是母嬰品類銷售的基石。
機遇與挑戰并存。母嬰電商市場潛力巨大,但競爭也日趨激烈,且消費者需求快速變化。若羽臣的未來發展,需持續深化對新生代家庭消費行為的洞察,在供應鏈效率、技術創新(如AI客服、VR產品體驗)、社會責任(如環保產品、公益倡導)等方面不斷突破。
若羽臣通過將“重視新生代寶媽消費訴求”這一理念深度融入其電子商務經營的各個環節,從營銷、運營到服務,構建了一個以用戶價值為核心的商業模型。這不僅是抓住當前母嬰電商機遇的關鍵,更是其在瞬息萬變的電商市場中構建長期競爭力的核心路徑。